Backpropagation:反向传播算法
解决的问题:有效计算百万维参数的梯度 $\nabla L(\boldsymbol{\theta})$ <= 更有效的Gradient Desent方法
核心 - 链式法则
根据链式法则:
Forward pass:对所有参数计算$\partial z/\partial{w}$
——-> 其实就是 $w$ 对应的输入
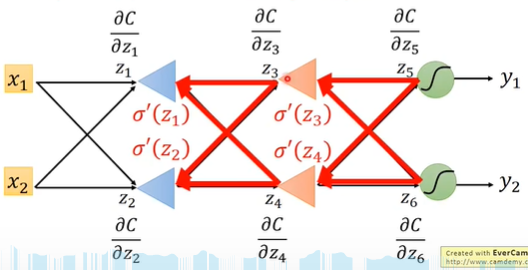
Backward pass:对所有激活函数的输入 $z$ 计算 $\frac{\partial C}{\partial z}$ ,其中 $C$ 表示某一维的Cross Entropy
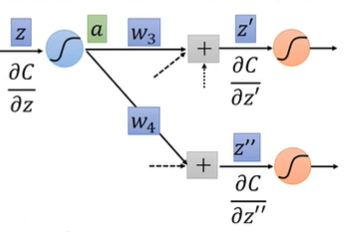
从另一个角度来看,可以把这个式子看作一个反向传播的neuron
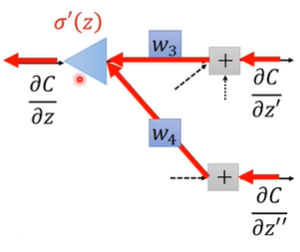
不同的是,在给定 $z$ 的情况下,$\sigma’(z)$ 是个常数,而不是激活函数。
用这种方法就可以从后往前依次算出每个 $z_i$ 的偏微分