Unsupervised Learning: Word Embedding
生成词向量是个非监督的过程,只有输入数据而不知道输出数据
这个问题不能用Auto-encoder来解(1-of-N encoding之间没有体现出词汇间的关联性)
Word Embedding
机器通过上下文学习一个单词的意思
Count based
- 如果两个单词经常同时出现,那么这两个单词的词向量彼此接近
Prediction based
给神经网络一个单词,预测下一个可能出现的单词(每个单词出现的机率)
用第一层的neurons代表一个单词:词向量(word vector)/词嵌入特征(word embedding feature) —> V(w)
Sharing Parameters : 当用多个单词预测下一个单词的时候,同维对应的权重 $w_i$、$w_j$ 相同
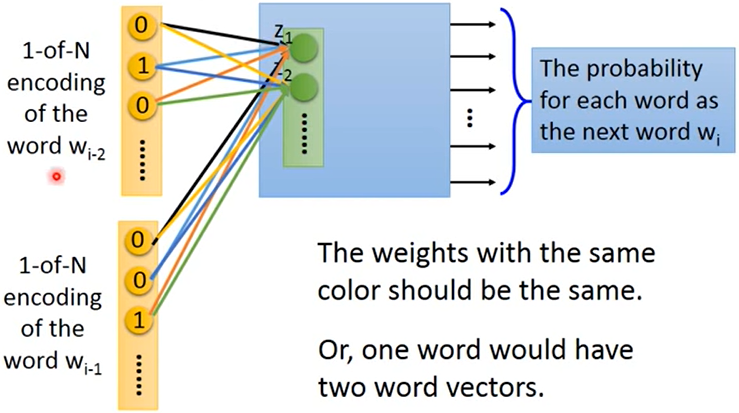
为什么:如果不这么做,交换单词的输入顺序将会得到不同的结果;可以减少参数量
怎么做:
给 $w_i$ 和 $w_j$ 相同的初始值
更新
Training : 最小化输出和目标词汇的交叉熵
不同的架构
- Continuous bag of word(CBOW) model:用上下文来预测中间可能出现的词汇
- Skip-gram:用中间的词汇预测上下文可能出现的词汇
其他应用
- Multi-lingual Embedding
- Multi-domain Embedding
- Semantic Embedding (document —> vector)
- 只用BOW描述一篇文章是远不够的(语序不同导致的意义不同)