卷积神经网络(一):CNN基本概念
引子:边界检测
在认识卷积神经网络CNN之前,我们先来看一个最简单的例子——边界检测(edge detection)。假设现在有一张6$\times$6的图片:
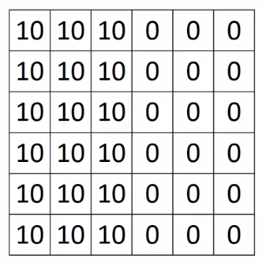
我们都知道,对于一张灰度图,像素值越大,颜色越亮,因此中间两个颜色的分界线就是我们要检测的边界。那么问题来了,怎么检测它呢?我们可以设计这样一个3$\times$3滤波器(filter,或者称为kernel,卷积核):
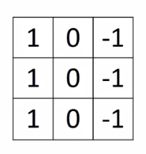
我们拿这个filter去和原来的图片作卷积,也就是当filter覆盖一块相同大小的区域后,将该区域内的元素与自己对应相乘,然后求和,按步长滑动覆盖整个图像,步长的概念后文会解释,下图的例子中步长为1,将得到一个4$\times$4的结果矩阵:
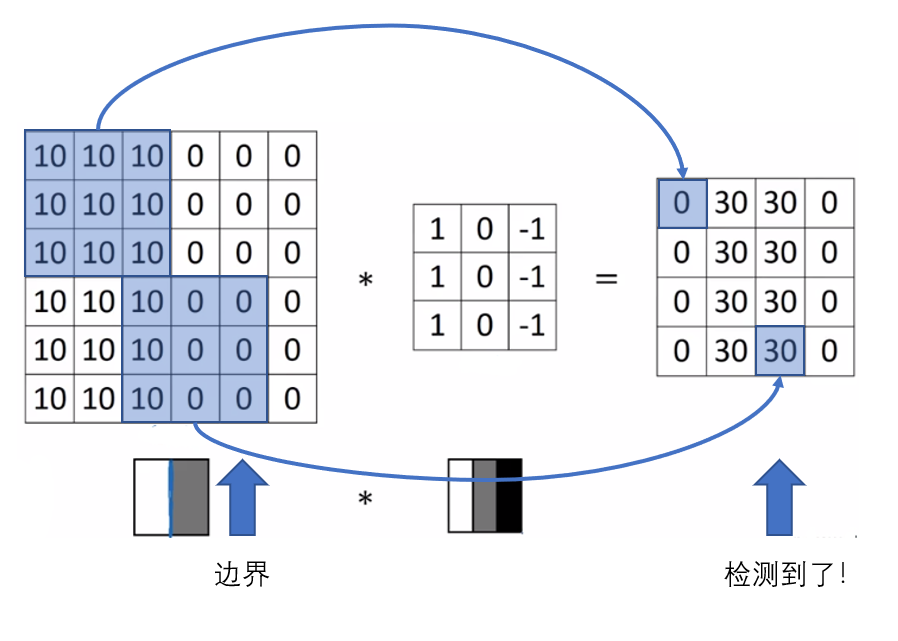
可以发现右边的图中间颜色浅,两边颜色深,说明原图片中间的边界被检测出来了。
上面这个例子说明了,我们可以通过设计特定的filter,让它去和图片作卷积,来识别出图片中的某些特征,例如边界。
上面这个filter用来检测垂直边界,同样的,我们也可以设计出一个检测水平边界的filter,把刚才的filter旋转90$^\circ$即可。对于其他特征,理论上总是可以通过精密的计算检验人工设计出合适的filter,然后CNN(Convolutional Neural Network,卷积神经网络),就可以通过这一个个不同的filter,不断地提取特征,从局部到整体,从而实现图像识别等工作。
那么问题又来了,对于刚才的图片只是简单的边缘检测,人工设计滤波器可以轻易实现,但是要知道,现实的图片中可能包含了成千上万中特征,想要一一设计出对应的filter,完全不现实。这就到神经网络发挥作用的时候了,这些filter,根本不需要我们去设计,只需要将每个filter中的各个数字看作一个参数,让机器通过大量的数据自己去学习它们就可以了,甚至还可以实现比人工计算更加合适的滤波器。
以上就是CNN的基本原理。
CNN的基本概念
Padding
为了构建卷积神经网络,Padding是一个基本的卷积操作。从上面的例子中我们发现,一个6$\times$6的图像经过3$\times$3的filter卷积之后变小了(4$\times$4),更普通地说,一个$n\times n$的图像,用一个$f\times f$的滤波器做卷积,得到的图像大小将变为$(n-f+1)\times (n-f+1)$,这样就会产生两个问题:
- 每做一次卷积图像就会缩小一次,这样没几次卷积图像就没了,尤其对于深度神经网络而言,是不希望发生的;
- 相较图像中心的点而言,边缘像素点在卷积中计算的次数很少,容易丢失边缘信息。
针对这两个问题的解决方法是,在每次做卷积之前,填充整个图像使得卷积后的图像大小和原始图像大小相同,同时,原图的边缘也能参与更多次的计算。通常,填充的像素值都为0。
参数p用来指定在原图周围填充的像素圈数,例如在上面的例子中,我们指定p=1,那么原来6$\times$6的图像的周围将多出一圈像素值为0的像素,从而变成一个8$\times$8的图像,在经过3$\times$3的filter后,得到的结果将是一个6$\times$6的图像,和原图一样大,没有缩小。
Padding常用的有两种方式:
- Valid:
p=0,即不经过任何像素填充;
- Same: 让卷积之后的图像大小不变的Padding方式
当我们使用Same方式时,如何计算参数p的具体值呢?假设我们现在有一个$n\times n$的图像,和一个$f\times f$的滤波器,在原图周围填充p圈像素后得到的图像大小为$(n+2p)\times (n+2p)$,那么卷积后得到的图像大小为$(n+2p-f+1)\times (n+2p-f+1)$,要使它和原图大小相等,则必须$n=n+2p-f+1$,从而得到$p=\frac{f-1}{2}$。
习惯上,在计算机视觉中,$f$通常是奇数,很少见到一个偶数的滤波器。
Stride
Stride(步长)是构建卷积神经网络的另一个基本操作,它决定了卷积核每次移动过几行/列像素,以下面7$\times$7图像卷积3$\times$3filter为例,可以清楚地了解Stride的作用:
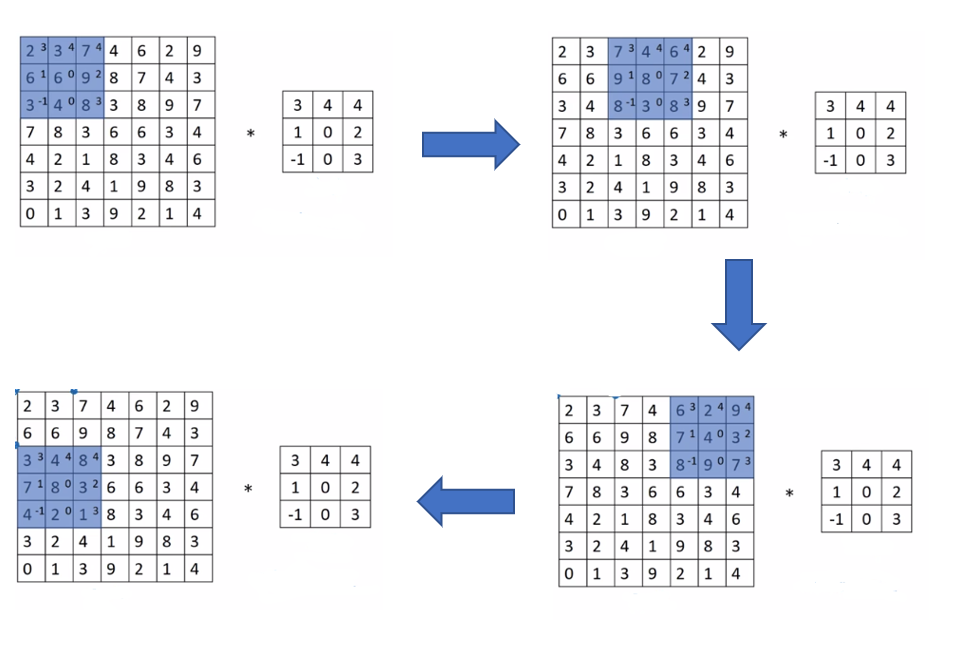
卷积得到的图像大小由下面这个公式给出:
当无法整除时向下取整,它的实际意义是,只有当filter完全在被卷积图像中时才能进行卷积操作。
Pooling
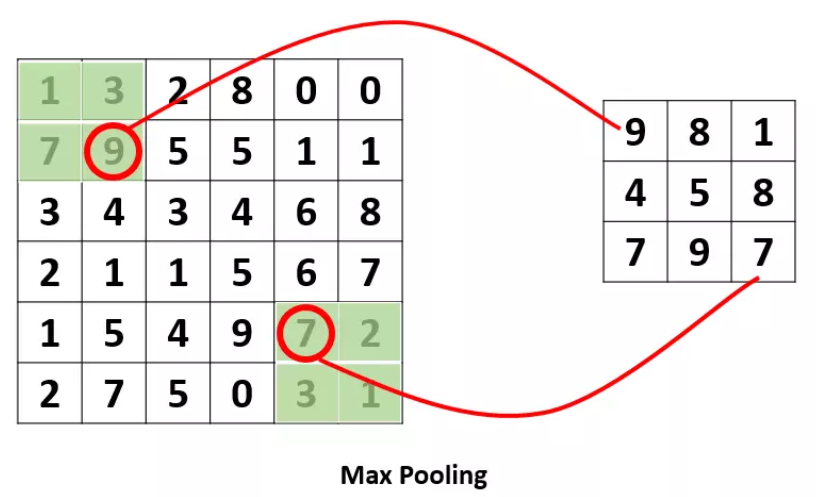
Pooling操作是为了提取一定区域内的主要特征,并减少参数的数量,防止模型过拟合,例如下面的Max Pooling,它采用了一个2$\times$2的窗口,步长为2,其作用是取每个2$\times$2的窗口中的最大值,构成最终的输出。
多通道(channels)图像卷积
我们在日常生活中所接触的图像通常是RGB图像,即除了长宽外,它还有RGB三个通道(channel),因此输入卷积神经网络的数据也不再是简单的长$\times$宽,而应该是长$\times$宽$\times$通道。那么相对应的,我们的filter也要从二维变化成三维,沿用上面的例子,filter的维度就要变成(3,3,3),其最后一维必须和输入的channel维度一致。
这时候的卷积运算,是三个channel的所有元素对应相乘后求和,换言之,之前是九个乘积的和,而现在则是27个乘积的和,因此输出图像的维度并不会发生变化,还是和二维时的一样。
但一般情况下,我们会使用多个filter来检测多个不同的特征,每个filter的输出对应最终输出图像的一层,例如上面的例子中,我们采用了4个不同的滤波器,假设分别是垂直边缘滤波器,水平边缘滤波器,45$^{\circ}$边缘滤波器,75$^{\circ}$边缘滤波器,那么输出图像维度将会是(4,4,4),最后一维取决于使用的滤波器个数,每一层图像对应了一个不同的特征。
单层卷积神经网络
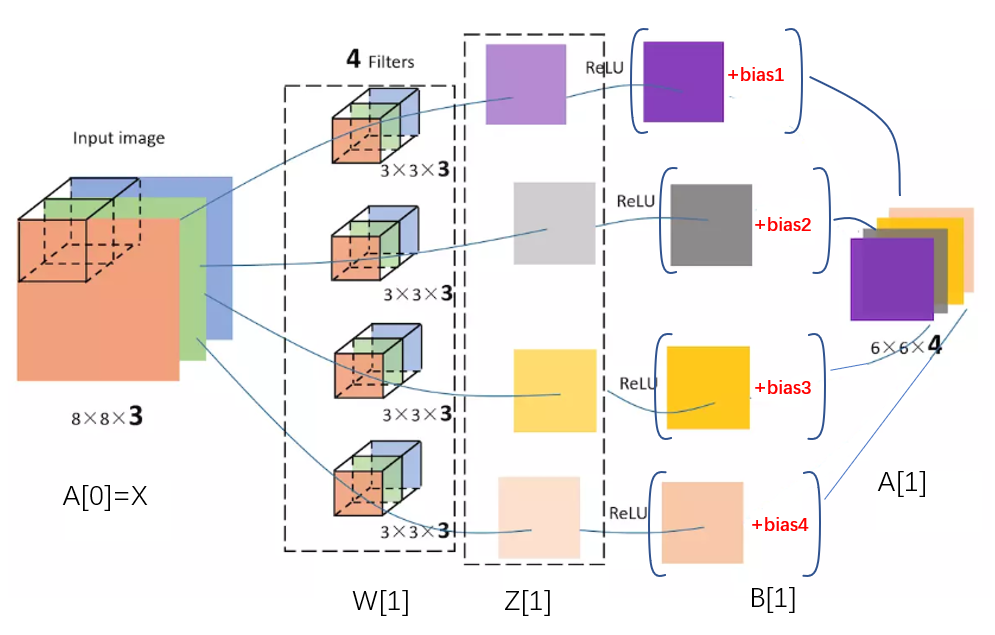
对卷积得到的输出图像加上偏置并由激活函数激活后,我们最终得到了第一层的输出,亦即第二层的输入:
CNN的组成结构
CNN包含了三种层
卷积层(Convolutional layer — CONV)
上面介绍的所有内容都是卷积层相关的,它由滤波器filter和激活函数构成,设计卷积层时涉及的超参数包括:filter的数量、大小、步长、是否填充、填充大小、偏差,以及激活函数的选择。
池化层(Pooling layer — POOL)
除了卷积层,卷积网络也经常使用池化层来缩小模型的大小,提高计算速度,同时提高所提取的特征的鲁棒性。
最常用的算法是Max Pooling,这在上文也提到过。最大化操作的功能是,只要在任何窗口内提取到某个特征,它都会保留在最大池化的输出里,换言之,如果在过滤器中提取到了某个特征,那么保留其最大值;如果没有提取到这个特征,那么这块区域中不存在这个特征,其中的最大值也还是很小。
另外还有一种不太常用的池化方法——平均池化(Average Pooling),顾名思义,它不取最大值而是计算平均值。
池化的超参数包括窗口大小$f$,步长$s$,以及池化方式。常用参数值为$f=2,s=2$,其效果相当于高度和宽度各减少一半,也有使用$f=3,s=2$的情况。池化层没有需要学习的超参数。
全连接层(Fully Connected layer —FC)
这就是我们之前学的神经网络中的最普通的层,就是一排神经元。因为这一层是每一个单元都和前一层的每一个单元相连接,所以称之为“全连接”。这里要指定的超参数无非就是神经元的数量,以及激活函数。
一个CNN的典型架构
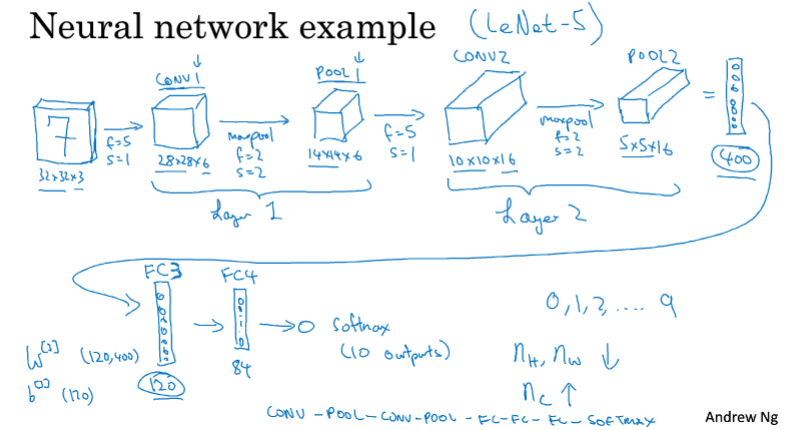
如上图,对一个输入的(32,32,3)的手写数字图像,经过第一次卷积(f=5,s=1,p=0,n=6,ReLU),得到(28,28,6)的CONV1,再经由最大池化层(f=2,s=2)得到(14,14,6)的POOL1,通常我们将CONV1和POOL1合称为Layer1。然后再过一次(f=5,s=1,p=0,n=16,ReLU)的卷积,得到(10,10,16)的CONV2,经过最大池化层得到(5,5,16)的POOL2,将POOL2展开(扁平化)即得到一个长为400的向量,后面的操作就与一般神经网络无异了(经过两个全连接层后变成长为84的向量,作为Softmax的输入)。
CONV(relu)-POOL-CONV(relu)-POOL-FC-FC-FC-Softmax
以上就是一个典型的CNN架构,在这个过程中我们可以发现,随着网络的深入,图像的长宽在不断减小,而通道数(深度)在不断增加。