Hexo:用Github搭建自己的博客网站!
作为一名程序猿,拥有一个自己的博客来记录学习和一闪而过的灵感是一件好处多多的事,既可以帮助自己进步,也可以在别人遇到类似问题的时候帮上忙,甚至还可以面试的时候装个*。当然,现在网络上的各类博客有很多,诸如大家耳熟能详的CSDN、博客园、简书等等,可以直接发表自己的文章,这些网站用户交互做的很好,并且贴心地支持Markdown。
然而自己购买域名和服务器专门来搭建博客网站,除了购买成本令人望而生畏外,光是花力气搭建网站、定期维护就需要可观的精力和时间。
那么,接下来就要隆重介绍今天的主角——hexo!
Hexo 简介
Hexo是一款基于Node.js的静态博客框架,网页托管在Github上,安装使用非常方便,完全是搭建博客的首选!
文章分为两个部分:
- hexo的初级搭建,github部署,以及个人域名的绑定
- hexo的基本配置,主题更换等
Let’s Go!
第一部分 hexo的初级搭建
Hexo搭建步骤
- 安装Git
- 安装Node.js
- 安装Hexo
- Github创建个人仓库
- 生成SSH添加到GitHub
- 将hexo部署到Github
- 设置个人域名
- 发布文章!
1. 安装Git
绝对不能不知道这个工具!不了解它的同学们!出门左转赶紧学起来!
- Windows
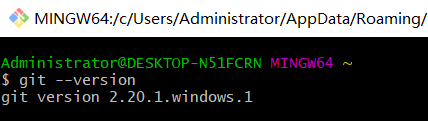
到Git官网下载Git Download ,安装后就可以用 Git Bash 命令行工具来使用Git了。安装好后,在Git Bash中输入git --version检验是否安装成功
- Linux
对Linux来说,就是一行代码的事儿
1 | sudo apt-get install git |
同样,安装好后,用git --version查看版本
2. 安装Node.js
hexo是基于Node.js编写的,所以需要一下Node.js和里面的npm工具。
- Windows
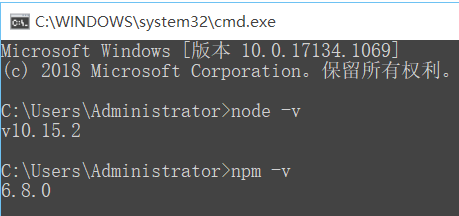
Node.js官网下载LTS版本,64位msi安装包,安装后分别在命令行(win+R输入cmd调用)输入node -v和npm -v检验PATH环境变量是否配置了Node.js
- Linux
1 | sudo apt-get install nodejs |
检验安装成功方式同Windows
3. 安装hexo
Windows环境进入Git Bash,Linux环境进入终端,开始搭博客啦!
首先新建一个文件夹blog来存放自己的博客,然后cd进入到这个文件夹下,输入下面的命令安装hexo
1 | npm install -g hexo-cli |
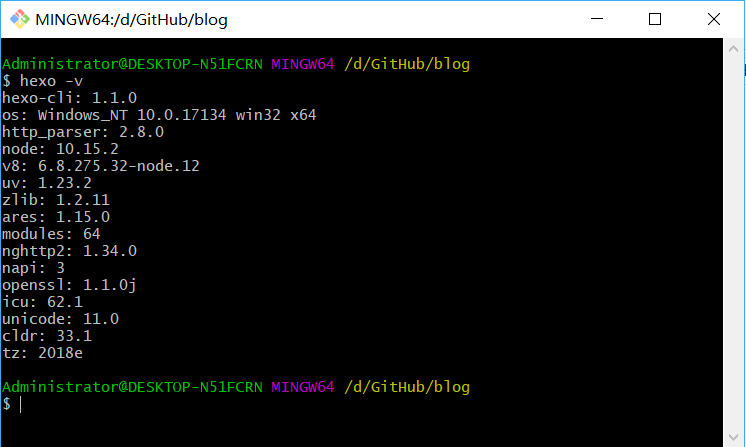
同样,安装完毕后需要hexo -v查看一下版本
至此需要的工具都安装完了。接下来初始化一下hexo
1 | hexo init blog |
这里的blog取什么名字都行
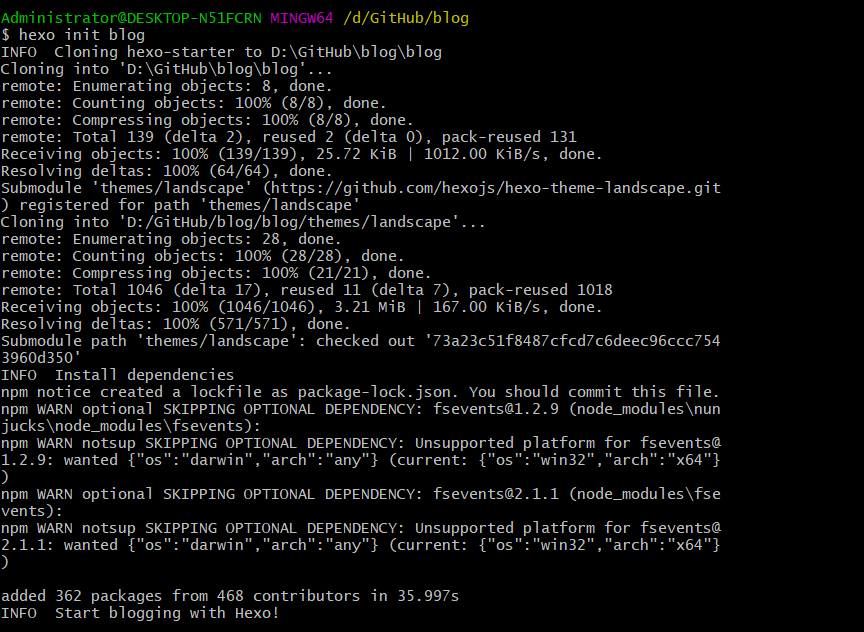
这时,在你的blog文件夹下会出现一个新的blog文件夹,进入到这个子文件夹后新建hexo
1 | npm install |
新建完成后,指定文件夹目录下应该有以下主要文件:
- node_modules:依赖包
- scaffolds:生成文章的一些模板
- source:用来存放自己的文章
- themes:网站主题
- __config.yml:博客的配置文件
1 | hexo g |
输入以上命令来开启hexo服务,在浏览器中输入localhost:4000就可以看到博客的初始化界面啦,现在还是有点丑丑的,大概长这样
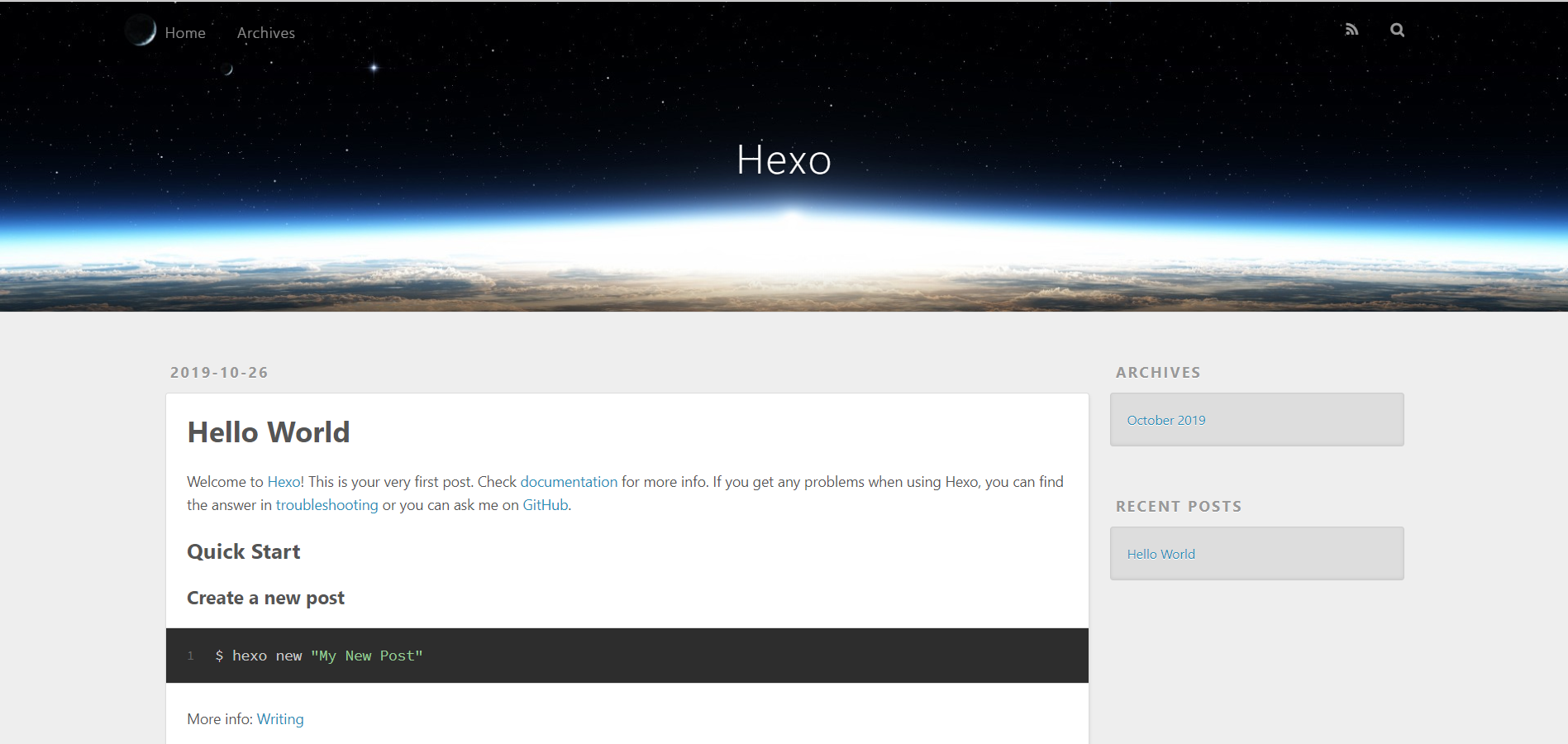
ctrl-c可以把服务关掉
此时再回到文件夹,你会发现多了一个public文件夹,这时用来存放生成的页面的。
4. GitHub创建个人仓库
上文提到过,hexo的静态网页是托管在GitHub中的,所以需要在GitHub中新建一个 和你用户名相同的 仓库,后面加 .github.io,也就是xxxx.github.io,只有这样将来要部署到GitHub Page的时候才会被识别。
5. 生成SSH添加到GitHub
回到Git Bash中,输入命令
1 | git config --global user.name "yourname" |
这里的yourname对应你的GitHub用户名,youremail对应你的GitHub注册邮箱,这样GitHub才能知道你是不是对应它的用户。不放心的话可以用下面两条命令来检查一下:
1 | git config user.name |
然后创建SSH,你可以选择密钥的保存位置,然后一路回车
1 | ssh-keygen -t rsa -C "youremail" |
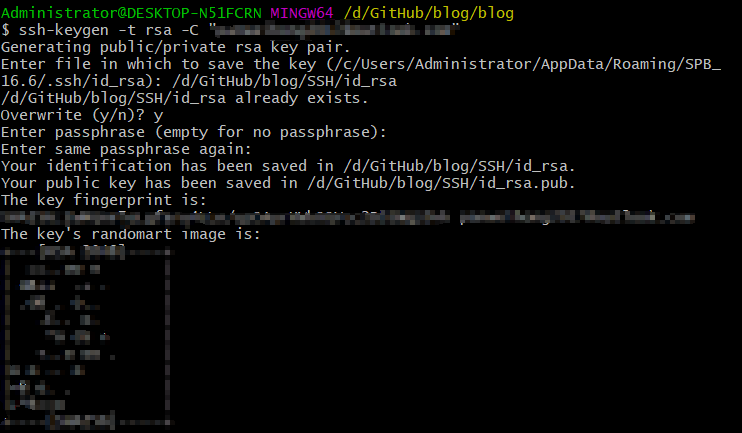
创建成功后,文件夹下会有两个文件,其中id_rsa是你这台电脑的私人密钥,id_rsa.pub是公共密钥。把公钥放在GitHub上,这样当你链接GitHub自己的账户时,她就会根据公钥匹配你的私钥,匹配成功才能通过git上传自己的文件到GitHub上。
在GitHub的setting(右上角头像下拉)中找到SSH and GPG keys的设置选项,点击New SSH key,把的id_rsa.pub里面的内容复制进去。
然后回到Git Bash,试试能否ssh通。

6. 将hexo部署到GitHub
在这步中,我们将要把hexo和GitHub关联起来,使得hexo生成的文章都部署到GitHub上。
打开网站配置文件_config.yml,拉到最后,将deploy部分修改为:
1 | deploy: |
其中,YourGithubName对应你的GitHub账户,并且注意:后必须要跟一个空格。
接下来安装deploy-git,也就是部署的命令,只有这样才能用命令将文章部署到GitHub上
1 | npm install hexo-deployer-git --save |
然后
1 | hexo clean |
- hexo clean:清除之前生成的东西,在日后新部署文章的时候可以使用,现在加不加没什么区别
- hexo generate:生成静态文章,缩写
hexo g - hexo deploy:部署文章,缩写
hexo d
出现下图说明部署成功
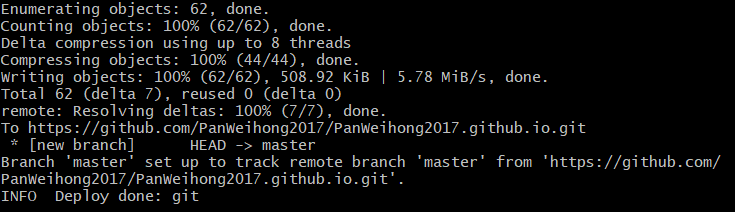
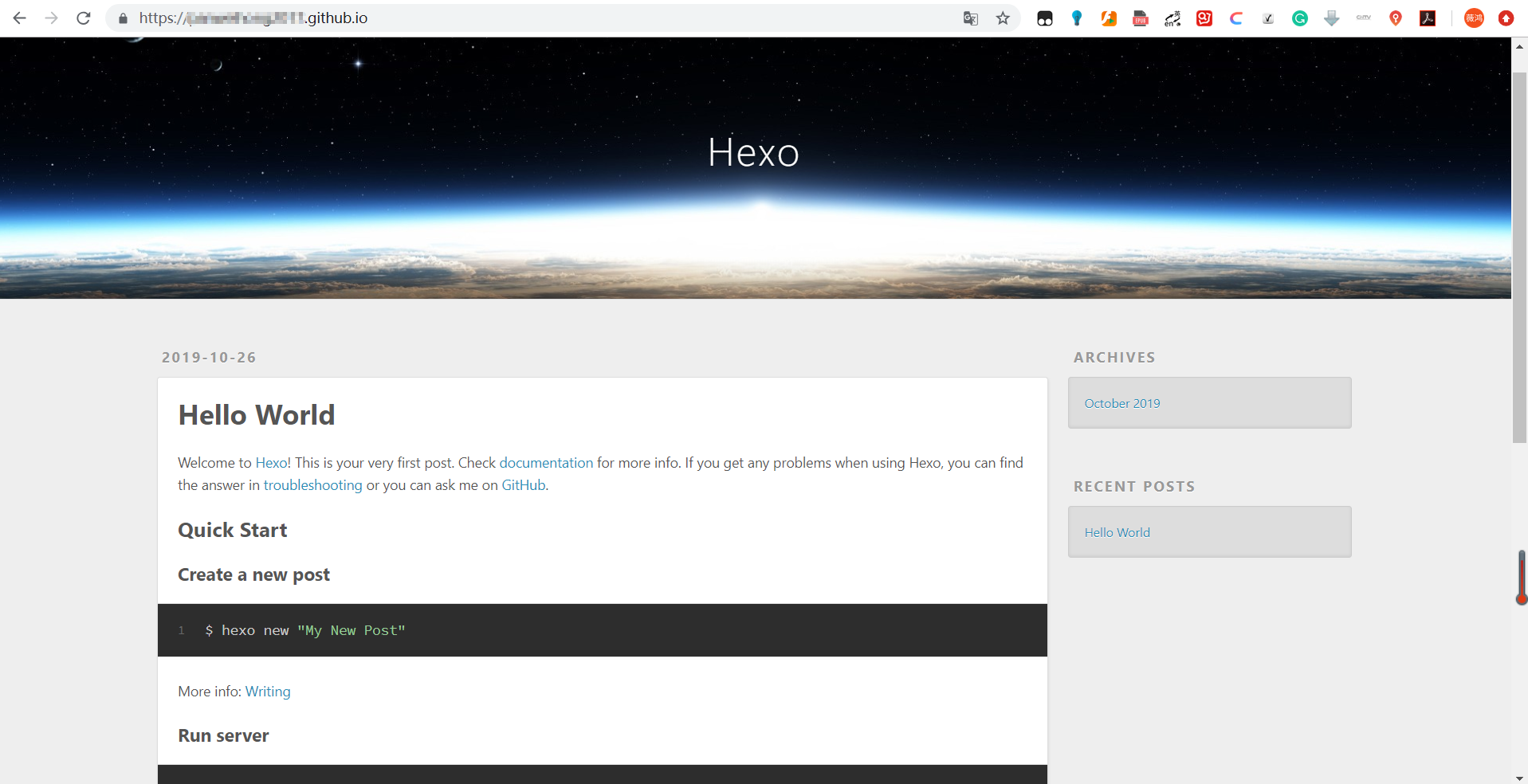
在浏览器地址栏中输入https://yourname.github.io就可以看到你的博客网站了!!像这样⬇
7. 设置个人域名
是不是觉得.github.io逼格太低了?那就来氪金设置个人域名吧!
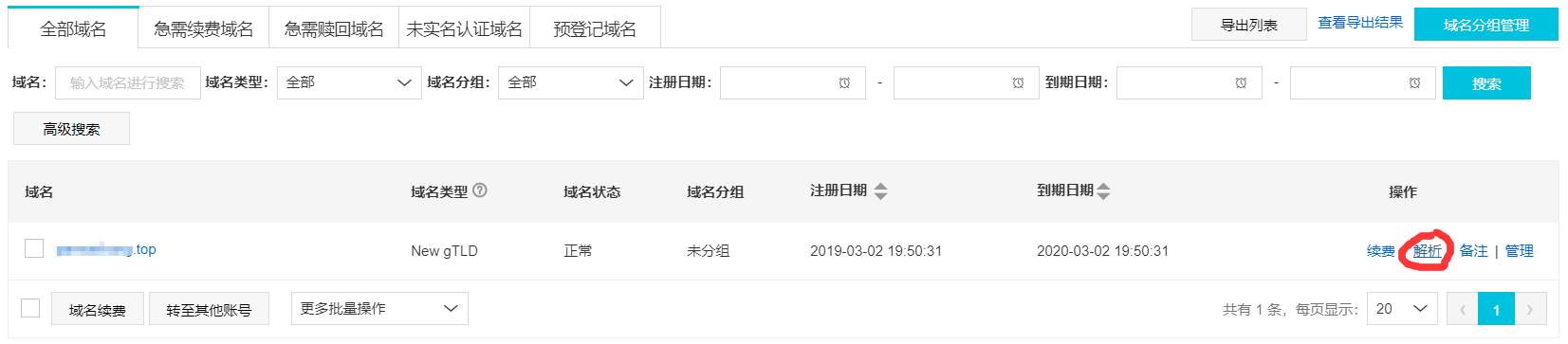
在阿里云上注册一个账号,再买一个域名,每个后缀的价格都不一样,最便宜的是.top,而应用最广泛的.com就比较贵。实名认证后进入控制台,展开左侧菜单栏,选择域名进入,你会看到自己购买的域名,点解析进入。
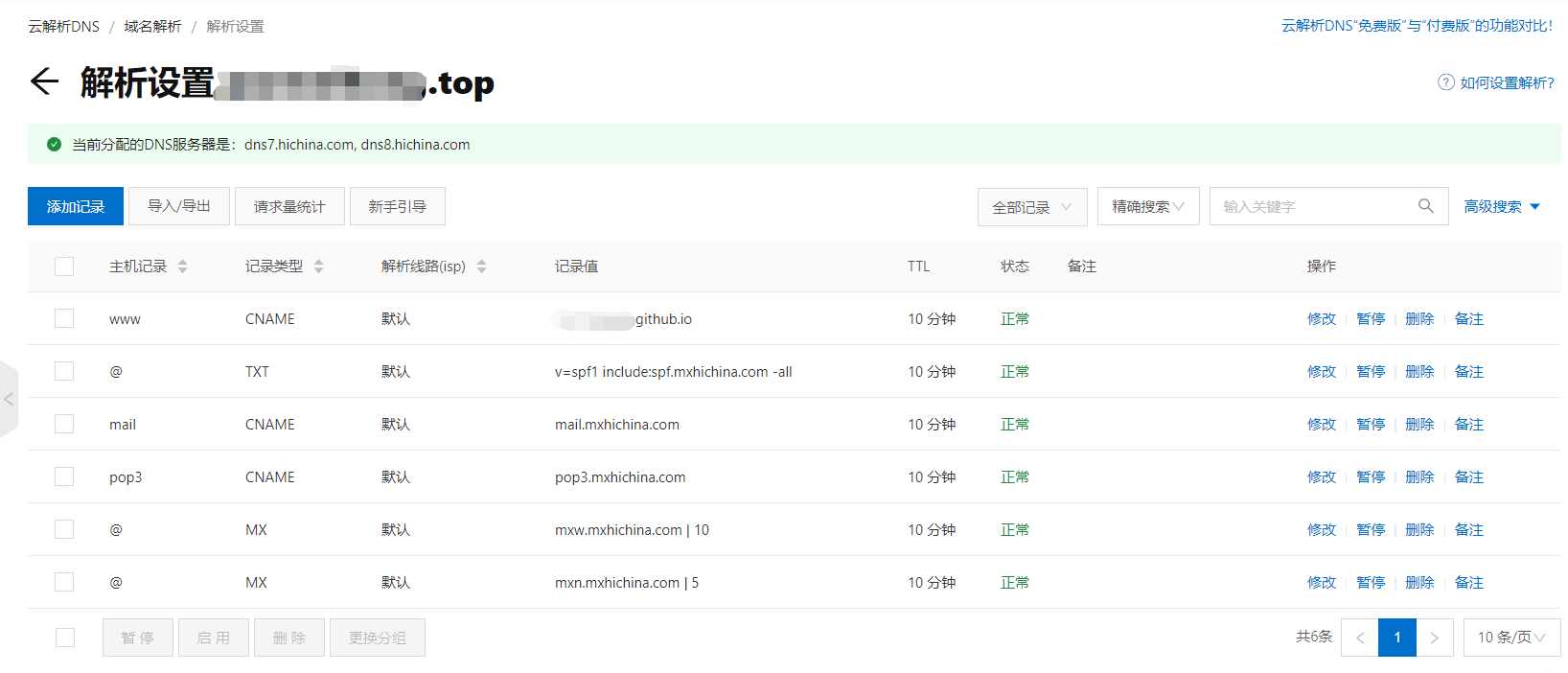
选择添加记录,设置如下:
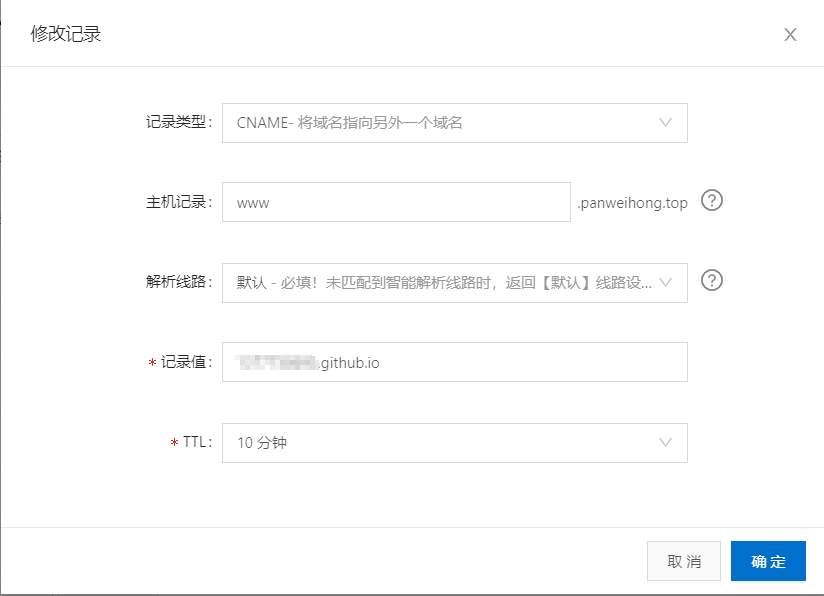
然后重新进入之前创建的仓库,点击Settings,在Options中下拉到GitHub Pages部分,在Custom domain中输入自己的域名。随后在博客文件夹blog下新建一个名为CNMAE的文件,不要加后缀,在里面写上自己的域名。最后重新在Git Bash中
1 | hexo clean |
等一小会儿时间,再打开浏览器,输入自己的域名,就可以看到刚才的初始化界面啦
接下来就可以开始写文章并发布了。
1 | hexo new "newArticleName" |
它会在source/_post文件夹下新建一个同名的markdown文件,编辑完成后,再
1 | hexo clean |
等一会儿就可以看到更新了,是不是很!简!单!
第二部分 hexo的基本配置
这部分我们来介绍hexo的基本配置、主题更换等。
1. hexo基本配置
blog文件夹下的_config.yml文件是整个hexo框架的配置文件,下面我们简单介绍几个常用配置,详细信息可以参考官方的配置描述。
网站 - Site
这部分参数包括了
- title:网站标题
- subtitle:网站副标题
- description:网站描述
- author:博客作者,也就是你的名字
- language:网站语言,中文使用
zh-CN - timezone:网站时区。默认使用电脑时区,或者自己设置
Asia/Shanghai
网址 - URL
这部分参数包括了
- url:网址,也就是你的网站域名
- root:网站根目录,默认为
\ - permalink:生成文章永久链接时的格式,不同的参数表示不同的链接格式,官方文件有详细说明,这里给出几种例子
| 参数 | 描述 |
|---|---|
:year/:month:day:title/ |
2019/10/26/hello-world |
:year-:month-:day-:title.html/ |
2019-10-26-hello-world.html |
:category/:title/ |
foo/bar/hello-world |
- permalink_defaults:永久链接格式中各部分的默认值
主题 - theme
theme参数决定了你选择什么主题,官网上有很多个主题,默认的是landscape,你可以在官网上下载自己喜欢的主题,放在theme文件夹下,同时将这个参数修改为主题文件夹名称即可。
个别文件变量 - Font matter
Font matter是Markdown文件最上方以---分隔的区域,用于指定文件自己的变量,例如:

预先定义的参数有:
| 参数 | 描述 |
|---|---|
layout |
布局 |
title |
标题 |
date |
创建日期 |
updated |
更新日期 |
comments |
开启评论 |
tags |
标签 |
categories |
分类 |
permalink |
覆盖文章默认网址 |
layout是在每一次创建新文件时使用的布局,也就是说new这个命令实际上是
1 | hexo new [layout] <title> |
hexo有三种不同的布局,对应了三种不同的存储路径
- post:这是hexo默认使用的布局,新建的文件保存在
source/_posts下
- page:如果想另起一页,就可以使用
1 | hexo new page board |
这句命令会让系统在source文件夹下创建一个board文件夹,以及文件夹中的index.md。
- draft:如果文章太长一次写不完,可以先写草稿文件,这样就不会被别人看到了。
1 | hexo new draft newArticle |
像上面例子中的mathjax参数是自己在主题文件夹下_config.yml中修改的,用来开启Latex的使用。
2. 更换主题
如果觉得默认主题不好看,那么就可以在官网主题中选择自己喜欢的进行修改。这里强烈推荐 NexT主题!非常简洁,赏心悦目。
直接从github上下载下来放到theme文件夹下,再把theme参数改成对应主题名字就ok了